Overview
According to legend, the first maxim of the Oracle of Delphi - said to spring from Apollo himself - is to know yourself. Or in Greek: nosce te ipsum, temet nosce. Repeated twice for emphasis and for nuance. Know yourself, to your own self be known. To know and have knowledge of yourself and then to process that knowledge. To know and to accept.
The purpose of what has been a decades-long interest for me is exactly that, but a little more. What value do the days 23 September 2004, or 8 July 1995, or 17 February 2017 have if they are remembered and known nowhere. Who were you on these days? We edit our lives like film editors, cutting out the boring bits - but are these not the foundation of who we are. The accumulation of a person are the days without monumental events - where a series of small and large decisions define you, who you were, and who you will be. And in that way this project is also a data diary of a person. In an age where social media networks, search engines, and a hungry horde of algorithms know us better than we know ourselves - this project is my redoubt. I should be the expert of myself, and I should endeavour to be better for that challenge.
This documentation set covers the mechanism of collecting, analysing, and displaying information about myself to myself. As such, the primary reader is me - but if you find something of use, please feel free to use it. There will be typos, broken processes, and periods of inactivity - because life doesn't stop for measurements.
Principles
Own all the data exclusively
Avoid storing any data on external services, even temporarily. This especially applies to health data.
Delete nothing
Preserve all collected and validated data, as it may have an unimagined use in the future.
Automate as much as possible
Automate as much of the collection of data as possible to avoid influencing the results. The process should not impinge on the output.
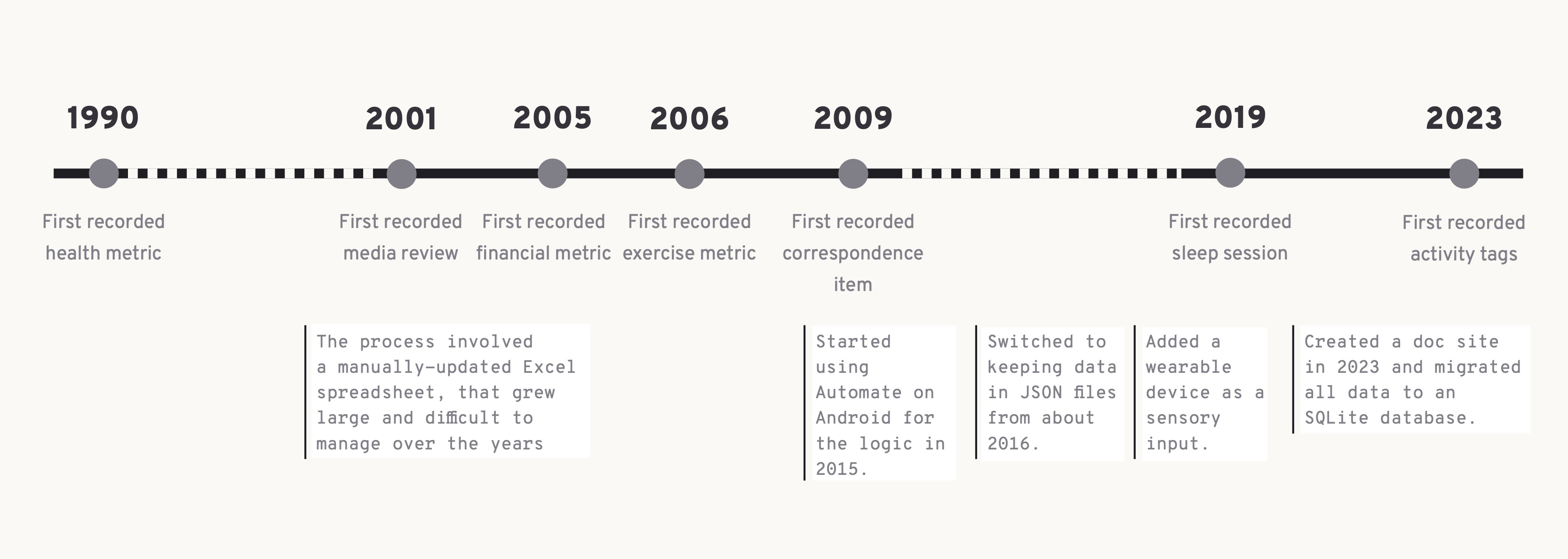
Data collected
This list may grow and contract over time, as new data sources are added and others are hidden.
Financial: Daily transactions (amount, time, date, category, subcategory, accounts, currency, location, brand, item, liquid balance), Investments (amount, asset type, region, growth/loss), Assets (details, cost, serial, logistics)
Health: Exercise (reps, sets, exercises, bpm, location, weather), Metrics (heart rate, resting heart rate, average heart rate, weight, height, haemotocrit, haemoglobin, eosinophils, basophils, lymphocytes, monocytes, neutrophils, platelet count, red cell count, white cell count, mean cell haemoglobin, mean cell volume, mean cell volume, mean corpuscular haemoglobin, red blood width, esr, systolic, diastolic, waist circumference, body fat, chest circumference, thigh circumference, body fat mass, skeletal muscle mass, visceral fat, body water, total cholesterol, hdl cholesterol, ldl cholesterol, triglyceride, pGlucose fasting, anion gap, bicarbonate, chloride, potassium, sodium, urea, creatinine, b12, ferritin, tsh, freet4, thyroid peroxidase, eye axis, eye cylinder, eye sphere, vo2max, avgspo2, sperm motility, sperm count), Sleep (sleep phases, duration, location, weather, air pressure, ambient light, sleep time, awake time)
Mental: Media (books, movies, tv, theatre, exhibitions), Productivity (focus sessions), Activities (reading, writing, media, art, games, meditation, technical, media, piano, design)
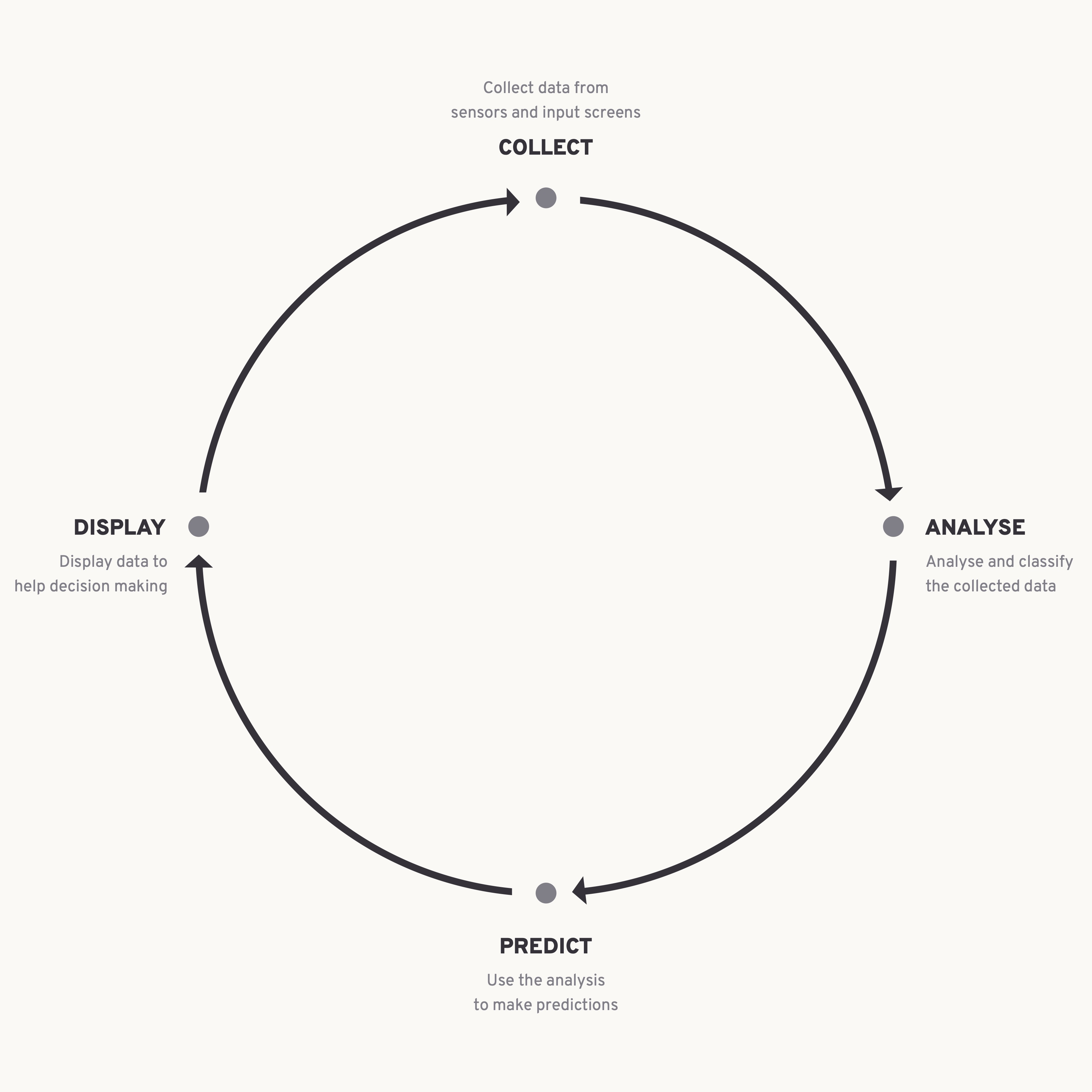
Diagram: Data cycle
Roadmap
Work on this project is planned and managed on this task board.